El habla es un método popular e inteligente en los tiempos modernos para interactuar con los dispositivos electrónicos. Como sabemos, hay muchas herramientas de reconocimiento de voz de código abierto disponibles en diferentes plataformas. Desde el principio de esta tecnología, se ha mejorado simultáneamente en la comprensión de la voz humana. Esta es la razón; ahora ha contratado a muchos profesionales que antes. El avance técnico es lo suficientemente fuerte como para hacerlo más claro para la gente común.
Herramientas de reconocimiento de voz de código abierto
La herramienta de reconocimiento de voz de código abierto no está muy disponible como el típico software que usamos en nuestra vida diaria en la plataforma Linux. Después de un largo camino de investigación, hemos encontrado algunas aplicaciones bien presentadas para usted con una breve descripción. Echemos un vistazo a los siguientes puntos!
1. Kaldi
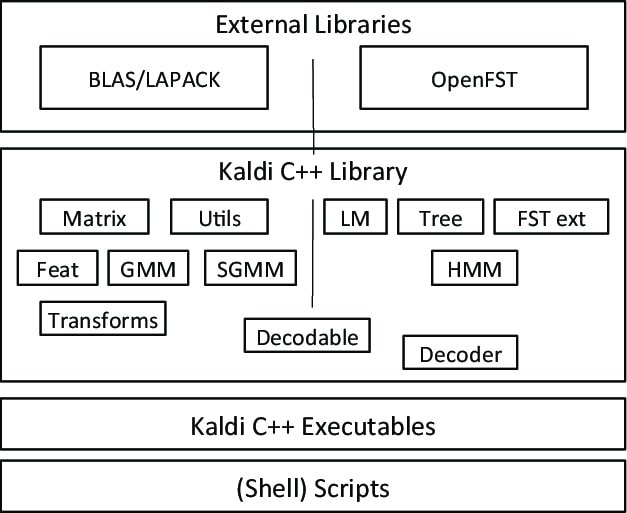
Kaldi es un tipo especial de software de reconocimiento de voz, iniciado como parte de un proyecto de la Universidad John Hopkins. Este kit de herramientas viene con un diseño extensible y escrito en el lenguaje de programación C++. Proporciona un entorno flexible y cómodo a sus usuarios con muchas extensiones para mejorar la potencia de Kaldi.

Características notables de Kaldi
- Una aplicación de reconocimiento de voz de código abierto, libre y flexible, bajo la licencia Apache.
- Funciona en múltiples plataformas, incluyendo GNU/Linux, BSD y Microsoft Windows.
- Proporciona soporte para instalar y configurar la aplicación en su sistema.
- Además del sistema de reconocimiento de voz, también soporta redes neuronales profundas y transformaciones lineales.
[su_button url=»https://github.com/kaldi-asr/kaldi» target=»blank» background=»#efb72d» size=»5″]Obtener Kaldi[/su_button]
2. CMUSphinx
CMUS Sphinx viene con un grupo de sistemas enriquecidos con varias funciones con varios paquetes prediseñados relacionados con el reconocimiento de voz. Es un programa de código abierto, desarrollado en la Universidad Carnegie Mellon. Usted recibirá esta herramienta de reconocimiento independiente de hablantes en varios idiomas, incluyendo francés, inglés, alemán, holandés, y más.

Características destacadas de CMUSphinx
- Es un sistema de reconocimiento de voz rápido y fácil de usar con una interfaz fácil de usar.
- Viene con un diseño flexible y un sistema eficiente, incluso en plataformas de bajos recursos.
- Proporciona herramientas de entrenamiento de modelos acústicos a través de su paquete Sphinxtrain.
- Ayuda a realizar diferentes tipos de tareas a través de sus útiles paquetes, incluyendo la detección de palabras clave, la evaluación de la pronunciación, la alineación, y más.
- Es una herramienta multiplataforma que soporta tanto sistemas Windows como Linux.
[su_button url=»https://cmusphinx.github.io/wiki/download/» target=»blank» background=»#efb72d» size=»5″]Obtener CMUSphinx[/su_button]
3. DeepSpeech
DeepSpeech es un motor de reconocimiento de voz de código abierto para convertir su voz en texto. Es una aplicación gratuita de Mozilla. Para ejecutar el proyecto DeepSearch en tu dispositivo, necesitarás Python 3.r o superior. Además, necesita un archivo con la extensión Git, a saber, Git Large File Storage. Se utiliza para versionar archivos grandes mientras se ejecuta en el sistema.
Características destacadas de DeepSpeech
- DeepSpeech utiliza el marco de trabajo TensorFlow para hacer que la transformación de voz sea más cómoda.
- Es compatible con la GPU NVIDIA, lo que ayuda a realizar inferencias más rápidas.
- Puede utilizar la inferencia de DeepSearch de tres maneras diferentes: El paquete Python, el paquete Node.JS o el cliente de línea de comandos.
- Cada vez que desee ejecutar este software en su sistema, deberá activar el entorno virtual mediante el comando Python.
- Necesita un entorno Linux o Mac para ejecutar esta aplicación.
[su_button url=»https://github.com/mozilla/DeepSpeech» target=»blank» background=»#efb72d» size=»5″]Obtener DeepSpeech[/su_button]
4. Wav2Letter++
WavLetter++ es una herramienta de reconocimiento de voz moderna y popular, desarrollada por el equipo de investigación de AI de Facebook. Es otro programa de código abierto bajo la licencia BCD. Este software de reconocimiento de voz superrápido fue construido en C++ y presentado con muchas características. Ofrece a sus usuarios la posibilidad de modelar el lenguaje, la traducción automática, la síntesis de voz y mucho más en un entorno flexible.

Características destacadas de Wav2Letter++
- Contiene una comunidad activa en plataformas populares como Facebook y el grupo Google para ayudar a sus usuarios en todo el mundo.
- WavLetter++ es un kit de herramientas rápido y flexible que utiliza la librería de tensores ArrayFire para lograr la máxima eficiencia.
- Le permite trabajar con un marco de trabajo de alto rendimiento como wav2letter++, que le ayuda a realizar una investigación y ajuste de modelos con éxito.
- Además, proporciona una documentación completa a través de las secciones del tutorial.
- En la carpeta de recetas, obtendrá las recetas detalladas para WSJ, Timit y Librispeech.
[su_button url=»https://github.com/facebookresearch/wav2letter» target=»blank» background=»#efb72d» size=»5″]Obtener Wav2Letter++[/su_button]
5. Julius
Julius es comparativamente un software de reconocimiento de voz de código abierto más antiguo desarrollado por Lee Akinobu. Esta herramienta está escrita en el lenguaje de programación C por los desarrolladores de Kawahara Lab, Universidad de Kyoto. Es una aplicación de reconocimiento de voz de alto rendimiento con un amplio vocabulario. Puede utilizarlo tanto en inglés como en japonés. Puede ser una gran opción si desea utilizarlo para fines académicos y de investigación.
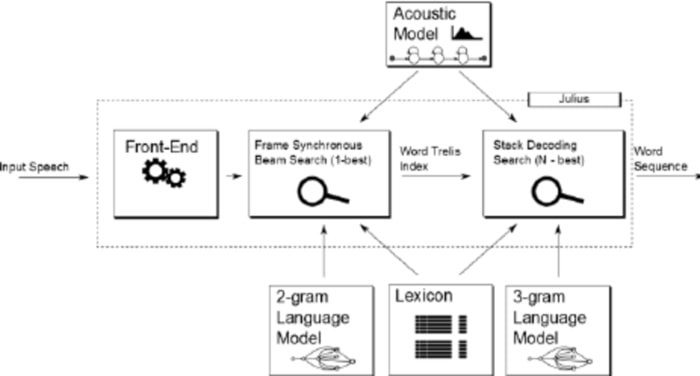
Características destacadas de Julius
- Julius es una aplicación altamente configurable que puede establecer diferentes parámetros de búsqueda para ajustar su rendimiento.
- Esta herramienta se basa en una estrategia de 2 pasadas que le proporciona un rendimiento en tiempo real y de alta calidad.
- Es un proyecto multiplataforma que se ejecuta en sistemas Linux, BSD, Windows y Android.
- Integrado con Julian, un analizador de reconocimiento gramatical.
- Además de soportar gramática basada en reglas, también proporciona salida de gráficos de Word, puntuación de confianza, rechazo de entrada basada en GMM, y muchas más facilidades.
[su_button url=»https://github.com/julius-speech/julius» target=»blank» background=»#efb72d» size=»5″]Obtener Julius [/su_button]
6. Simon
Simon viene con un software de reconocimiento de voz moderno y fácil de usar, desarrollado por Peter Grasch. Es otro programa de código abierto bajo la Licencia Pública General de GNU. Usted es libre de usar Simon en ambos sistemas Linux y Windows. Además, proporciona la flexibilidad para trabajar con cualquier idioma que desee.
Características notables de Simon
- Utilizando su calculadora controlada por voz, Simon ofrece la posibilidad de realizar diversas operaciones aritméticas.
- Compatible con Skype y otros programas VOIP populares para establecer un sistema de comunicación fácil con amigos y familiares.
- Permite a los usuarios ver presentaciones de diapositivas y vídeos, escuchar música y mucho más con unos sencillos comandos de voz.
- Además, es una herramienta esencial para leer periódicos y navegar por Internet.
[su_button url=»https://simon.kde.org/download» target=»blank» background=»#efb72d» size=»5″]Obtener Simon[/su_button]
7. Mycroft
Mycroft viene con un asistente de voz de código abierto fácil de usar para convertir la voz en texto. Está considerado como una de las herramientas de reconocimiento de voz de Linux más populares en la era moderna, escrita en Python. Permite a los usuarios hacer el mejor uso de esta herramienta en un proyecto científico o en una aplicación de software empresarial. Además, puede ser utilizado como un asistente práctico, que puede decirle la hora, la fecha, el tiempo, y más como estos.

Características destacadas de Mycroft
- Integrado con los medios sociales y plataformas profesionales más populares, incluyendo Facebook, Github, LinkedIn, y más.
- Puede ejecutar esta aplicación en diferentes plataformas de software y hardware. Puede ser un escritorio o un frambuesa Pi.
- Además de ser un asistente de voz inteligente, proporciona la facilidad de la grabación de audio, aprendizaje automático, biblioteca de software, y más.
- Permite a los usuarios convertir el lenguaje natural en datos legibles por máquina a través de Adapt, un analizador de intenciones de Mycroft.
[su_button url=»https://mycroft.ai/» target=»blank» background=»#efb72d» size=»5″]Obtener Mycroft [/su_button]
8. OpenMindSpeech
Open Mind Speech es una de las herramientas esenciales de reconocimiento de voz de Linux que tiene como objetivo convertir su voz en texto de forma gratuita. Es parte de la Open Mind Initiative, lleva a cabo su funcionamiento, especialmente para los desarrolladores. Este programa fue introducido con diferentes nombres como VoiceControl, SpeechInput y FreeSpeech antes de obtener el nombre actual.

Características destacadas de OpenMindSpeech
- Utiliza el entorno Overflow en la operación de reconocimiento de voz para flexibilizar las aplicaciones complejas.
- Open Mind Speech es mayormente compatible con plataformas basadas en Linux y UNIX.
- A través de Internet, puede recopilar datos de voz de los ciudadanos electrónicos, que son los contribuyentes de los datos brutos.
[su_button url=»http://freespeech.sourceforge.net/» target=»blank» background=»#efb72d» size=»5″]Obtener OpenMindSpeech [/su_button]
9. SpeechControl
Speech Control es una aplicación de reconocimiento de voz libre, adecuada para cualquier distribución de Ubuntu. Viene con una interfaz gráfica de usuario basada en Qt. Aunque todavía se encuentra en su fase inicial de desarrollo, puede utilizarlo para su proyecto simple.
Características destacadas de SpeechControl
- Speech Control es un programa de código abierto bajo la Licencia Pública General (GPL).
- Su objetivo es trabajar como un asistente virtual que proporciona una guía de tareas repetitivas para ejecutar el proceso sin problemas.
- Es principalmente adecuado para plataformas basadas en Linux.
- Además, proporciona documentación de usuario fácil de entender con detalles del proyecto.
[su_button url=»https://wiki.ubuntu.com/SpeechControl» target=»blank» background=»#efb72d» size=»5″]Obtener SpeechControl[/su_button]
10. Deepspeech.pytorch
Deepspeech.pytorch es otra aplicación de reconocimiento de voz de código abierto mencionable que es, en última instancia, la implementación de DeepSpeech2 para PyTorch. Contiene un conjunto de potentes redes basadas en la arquitectura DeepSpeech2. Con muchos recursos útiles, puede ser utilizado como una de las herramientas esenciales de reconocimiento de voz de Linux para la investigación y el desarrollo de proyectos.

Características notables de Deepspeech.pytorch
- Soporta el aumento de ruido que ayuda a aumentar la robustez en el momento de cargar el audio.
- Para enviar la petición de publicación al servidor, proporciona un script básico del servidor.
- Soporta varios conjuntos de datos para descargar, incluyendo TEDLIUM, AN4, Voxforge y LibriSpeech.
- Le permite añadir ruido a los datos de entrenamiento a través de la inyección de ruido.
- Soporta Visdom y Tensorboard para visualizar el entrenamiento en experimentación científica.
[su_button url=»https://github.com/SeanNaren/deepspeech.pytorch» target=»blank» background=»#efb72d» size=»5″]Obtener Deepspeech.pytorch[/su_button]
Reflexión Final
Por lo tanto, hemos alcanzado el punto final en las herramientas de reconocimiento de voz de código abierto para Linux. Hope, tienes información completa sobre este tema. Las aplicaciones mencionadas anteriormente son gratuitas, fáciles de usar y están listas para formar parte de su proyecto académico o personal.
¿Cuál prefieres más? Si tiene otras opciones, no dude en hacérnoslo saber. Saluditos!!